EVEREST OVERVIEW
PROJECT SUMMARY
The distributed and heterogeneous nature of the data sources in High Performance Big Data Analytics (HPDA) applications pushes towards novel computing systems that combine HPC, Cloud, and IoT solutions (for efficient and distributed computation closer to the data) with Artificial Intelligence (AI) algorithms (for knowledge extraction and decision making). The creation of future Big Data systems will be data-driven, but will also feature complex heterogeneous and reconfigurable architectures that must be customized depending on the nature and locality of the data, and the type of learning/decisions to be performed.
The EVEREST project aims at developing a holistic approach for co-designing computation and communication in a heterogeneous, distributed, scalable, and secure system for HPDA. This is achieved by simplifying the programmability of heterogeneous and distributed architectures through a “data-driven” design approach, the use of hardware-accelerated AI, and an efficient monitoring of the execution with a unified hardware/software paradigm. EVEREST proposes a design environment that combines state-of-the-art, stable programming models, and emerging communication standards with novel and dedicated domain-specific extensions.
PROject Concept
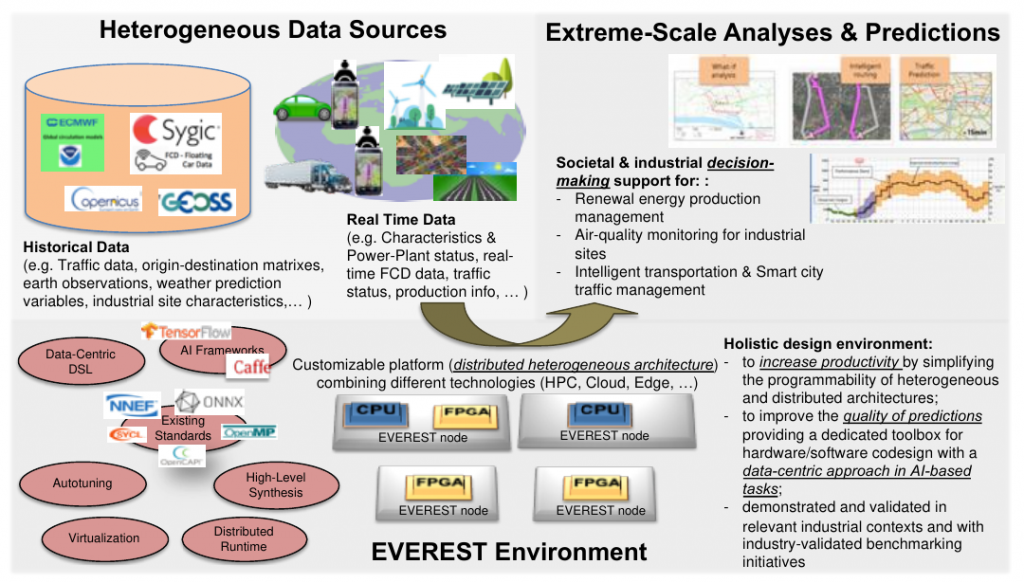
EVEREST aims at proposing a high-performance, distributed and heterogeneous hardware architecture and a companion design environment. The multi-node hardware architecture seamlessly combines CPUs and coherent FPGA accelerators for cloud computing, and disaggregated FPGA devices for edge computing. The design environment uses state-of-the-art programming models, emerging communication standards, and novel domain-specific extensions in combination to provide characteristics of algorithms and data, to better exploit data parallelism, to improve the dynamic control of the distributed execution, and to enforce security. The EVEREST approach will be validated on three industry-relevant applications.
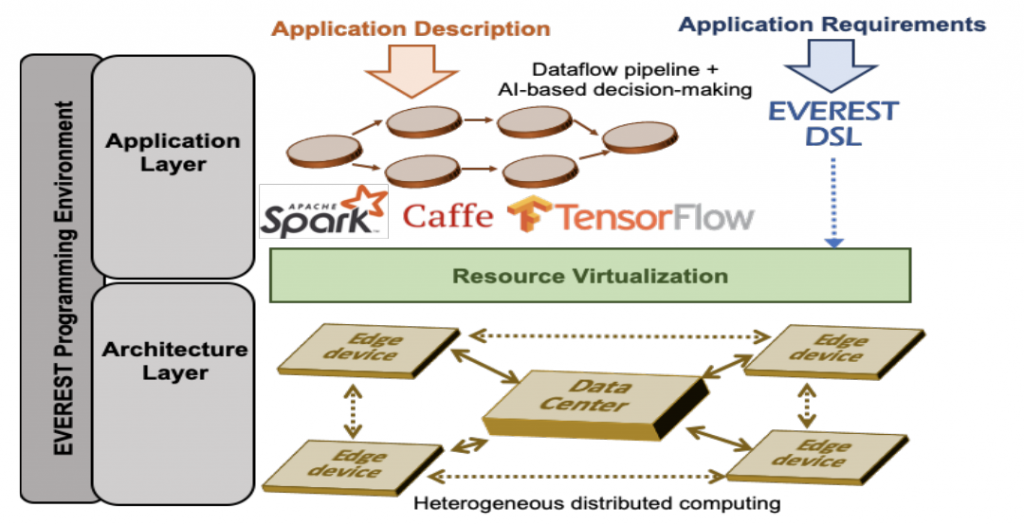
The EVEREST design environment simplifies the description, optimization, and implementation of extreme-scale Big Data applications (with multiple data sources) onto heterogeneous and distributed architectures having different computational paradigms and requirements. To model the applications, EVEREST combines high-level libraries which describe the workflow pipeline, DSLs, existing AI libraries and frameworks, and communication libraries. To co-design application optimization and architecture, EVEREST offers the generation of optimized code variants, reconfigurable accelerators, and a novel virtualized runtime environment.
PROject Organization
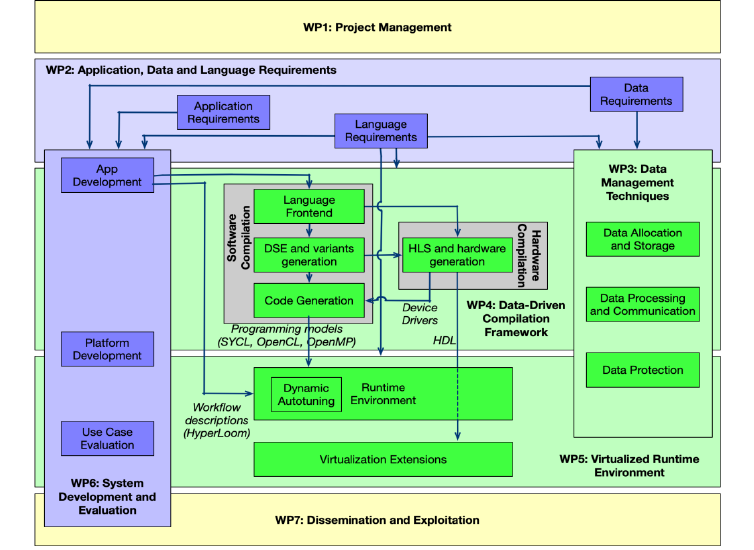
EVEREST is a new ICT-51-2020 – Big Data technologies and extreme-scale analytics – project lead by IBM RESEARCH GMBH. The Project Coordinator is Christoph Hagleitner (IBM Zurich), the Scientific Coordinator is Christian Pilato (Politecnico di Milano) and the duration is 36 42 months (The project has been extended by 6 months): October 2020 – September 2023 March 2024.